[빅데이터를 지탱하는 기술] 빅데이터 입문기 #2
첫번째 챕터에선 다음과 같은 내용에 대해서 알아볼 것이다.
- Hadoop과 NoSQL 데이터베이스의 역할과 데이터 웨어하우스를 중심으로 한 기술과의 차이?
- 데이터 파이프라인?
- 대화형 데이터 처리
- 스프레드시트와 BI 도구를 사용해 데이터의 변화 모니터링
배경 빅데이터의 정착
과거부터 데이터에 대한 처리는 항상 있었다. 단, 처리 속도와 방법에 문제때문에 하지 못하고 있었다.
지금은 이러한 문제가 해결되었기 때문에 빅데이터가 세상에 나오게 되었다.
빅데이터 기수의 요구 - Hadoop과 NoSQL
기존의 RDB로 취급할 수 없을 정도의 데이터가 쌓이게 되었다.
Hadoop - 다수의 컴퓨터에서 대량의 데이터 처리
여러 대의 컴퓨터를 관리하는 프레임워크
구글의 분산처리 프레임워크인 MapReduce를 참고하여 개발됨
초기엔 Java로 프로그래밍 해서 데이터 처리를 해야 했다.
이후에 Hive라는 쿼리언어를 통해 데이터를 다룰 수 있게 되었음
NoSQL - 읽기/쓰기 분산 처리가 강점
기존 RDB의 문제를 해결하기 위해 여러 NoSQL이 등장.
- Key-Value 기반
- JSON 같은 문서 저장
- 높은 확장성을 제공하는 와이드 칼럼 스토어
등등...
각각의 목표에 따라 개발됨.
RDB보다 읽기 쓰기가 빠르고, 분산처리에 강하다는 특징이 있음
온라인으로 접속하는 데이터베이스
Hadoop과 NoSQL의 조합 - 현실적인 비용으로 대규모 데이터 처리 가능
과거엔 비용이라는 현실적인 문제가 있었음, 기술 부족.
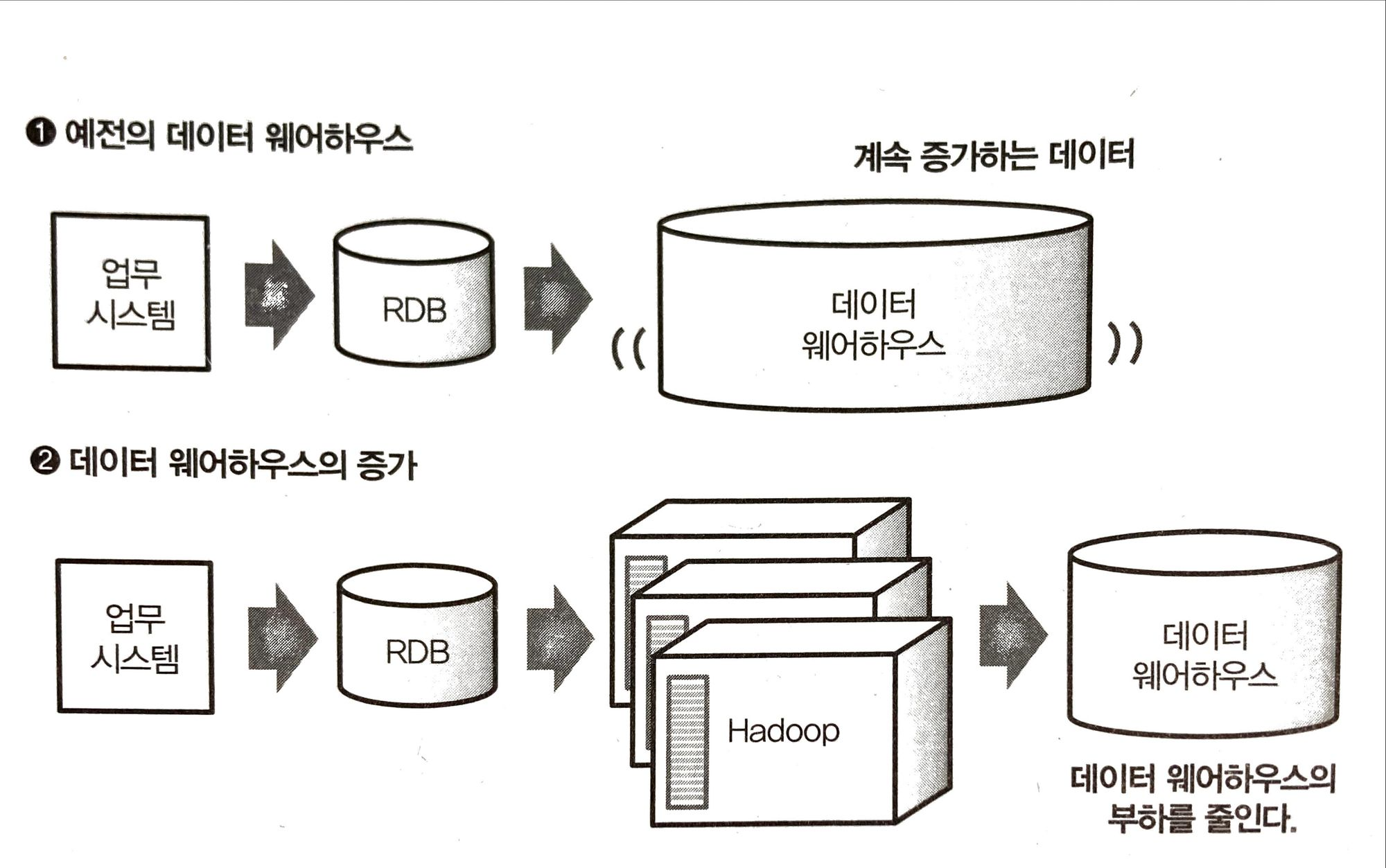
분산 시스템의 비즈니스 이용 개척 - 데이터 웨어하우스와 공종
사실 이전에도 엔터프라이즈 데이터 웨어하우스 (or 데이터 웨어하우스)를 도입해서 분석하고 있었음
DW의 장점은 대량의 데이터 처리가 가능함
단점은 안정성을 위해 SW와 HW가 합쳐진 appliance 장비로 제공됨
→ 데이터 용량 증설이 불편함. 확장성이 떨어짐
→ 빠르게 데이터를 처리해야 되는 것은 Hadoop, 중요한 정보는 데이터 웨어하우스에 보관
직접 할 수 있는 데이터 분석 폭 확대
클라우드 서비스와 데이터 디스커버리로 가속하는 빅데이터의 활용
클라우드의 보급을 통해 빅데이터 활용이 커짐
분산처리를 위해 여러 대의 컴퓨터를 준비하기 어려웠는데, 클라우드가 이를 해결해줌
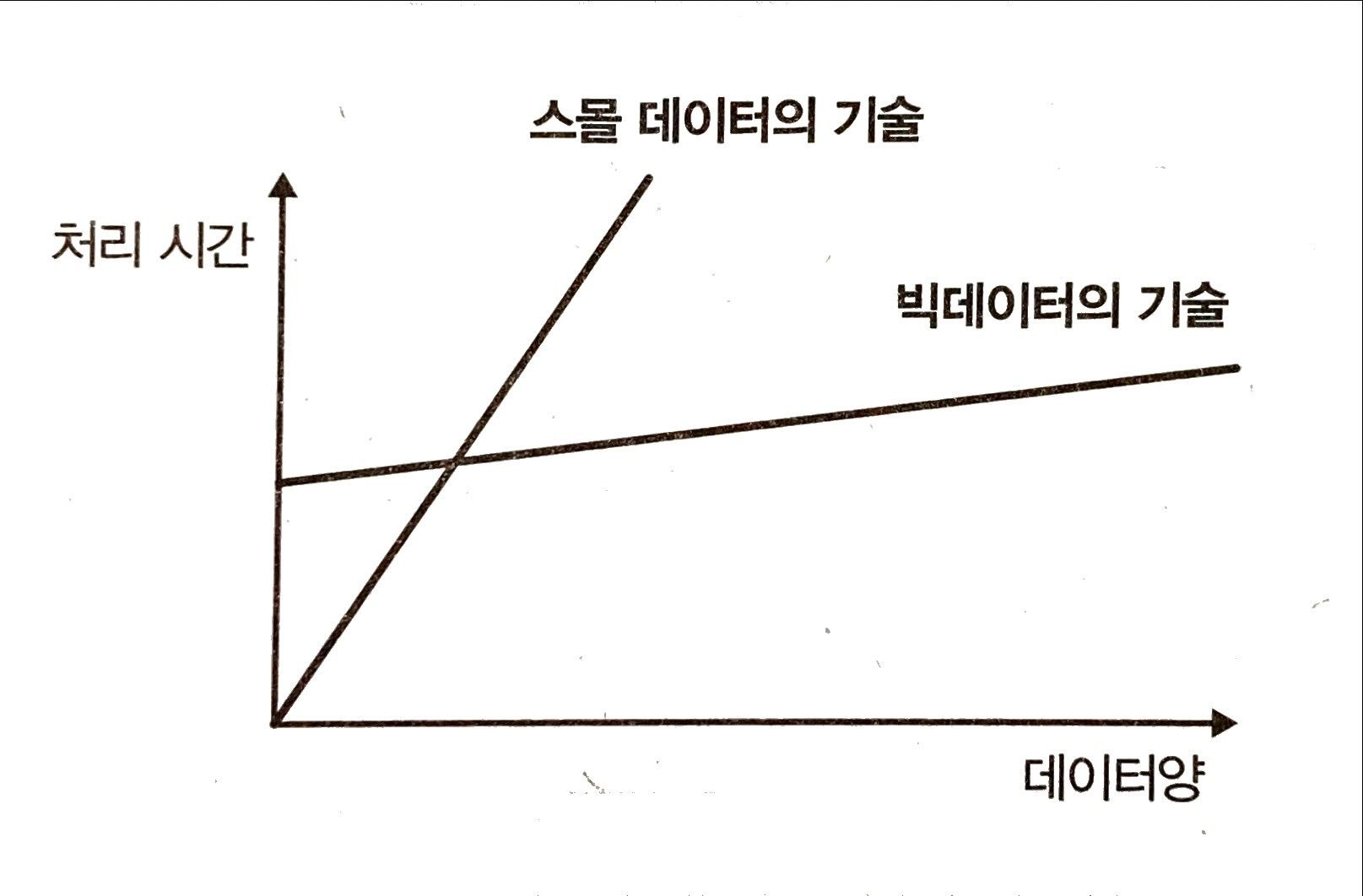
스몰데이터 vs 빅데이터?
한 대의 컴퓨터에서 충분히 처리 가능한 데이터를 스몰 데이터라 함
스몰 데이터, 빅데이터 모두 단순한 데이터이며 크기의 차이다.
하지만 데이터가 증가할수록 처리 속도는 차이를 보인다.
이를 얼마나 효율적으로 처리하느냐가 중요한 문제이다.
빅 데이터와 스몰 데이터
데이터 디스커버리의 기초 지식 - 셀프 서비스용 BI 도구
데이터 디스커버리란 저장된 데이터를 시각화하여 보기 위한 기술이다.
대화형으로 데이터를 시각화하여 가치 있는 정보를 찾으려고 하는 프로세스를 말한다.
효율과 편리성을 갖추고 있으며, 기술적 지식이 낮더라도 사용할 수 있음
빅데이터 시대의 데이터 분석 기반
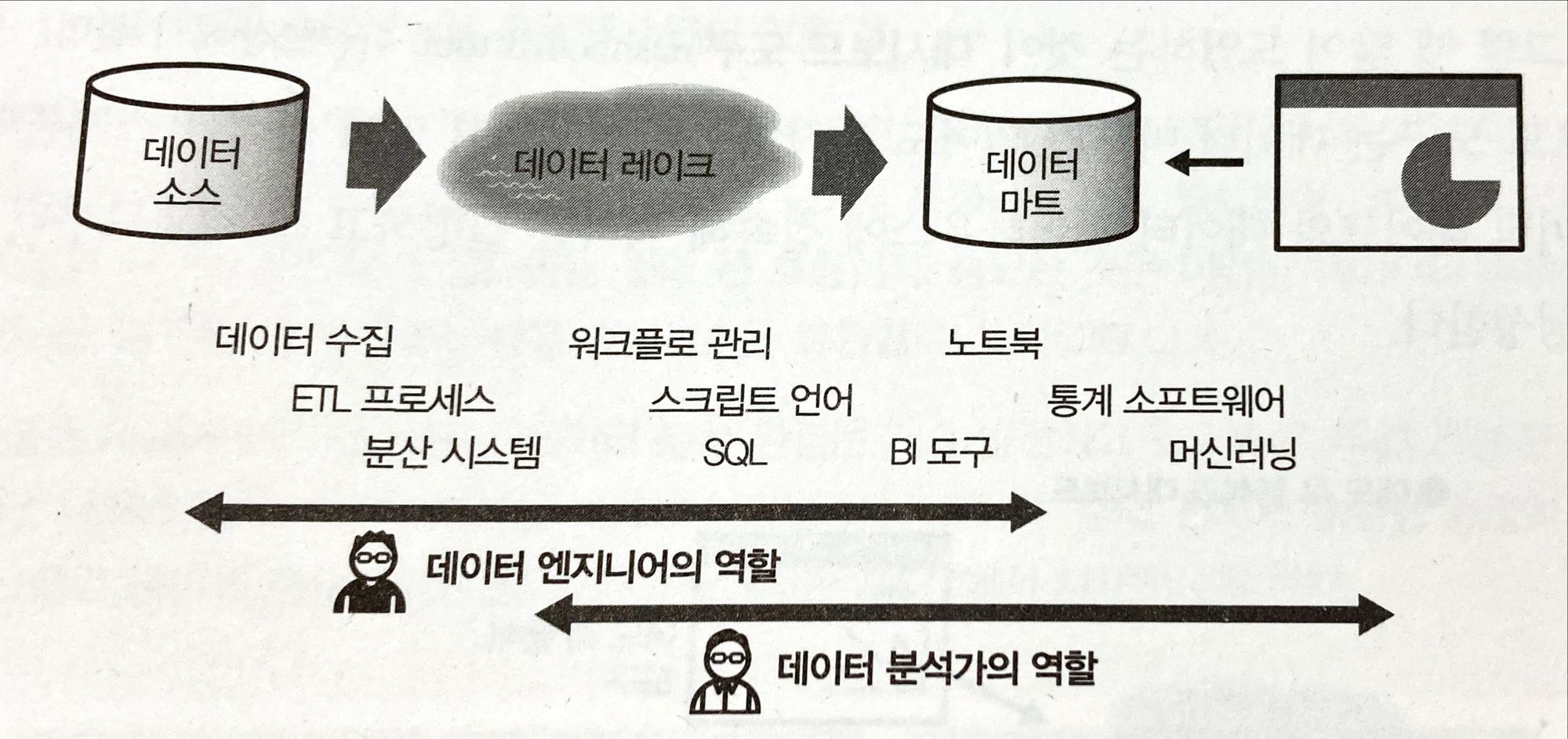
빅데이터와 DWH의 차이는 다수의 분산 시스템을 조합하여 확장성이 뛰어난 데이터 처리 구조를 만드는 것이다.
빅데이터 기술 - 분산 시스템을 활용해서 데이터를 가공해 나가는 기술
→ 분산 시스템을 활용해 데이터를 순차적으로 가공해 가는 일련의 구조이다.
데이터 파이프라인 - 데이터 수집에서 워크플로 관리까지
일반적으로 차례대로 전달해 나가는 데이터로 구성된 시스템을 데이터 파이프라인이라고 한다.
어디서 데이터를 수집하고, 무엇을 실현하고 싶은지에 따라 달라짐
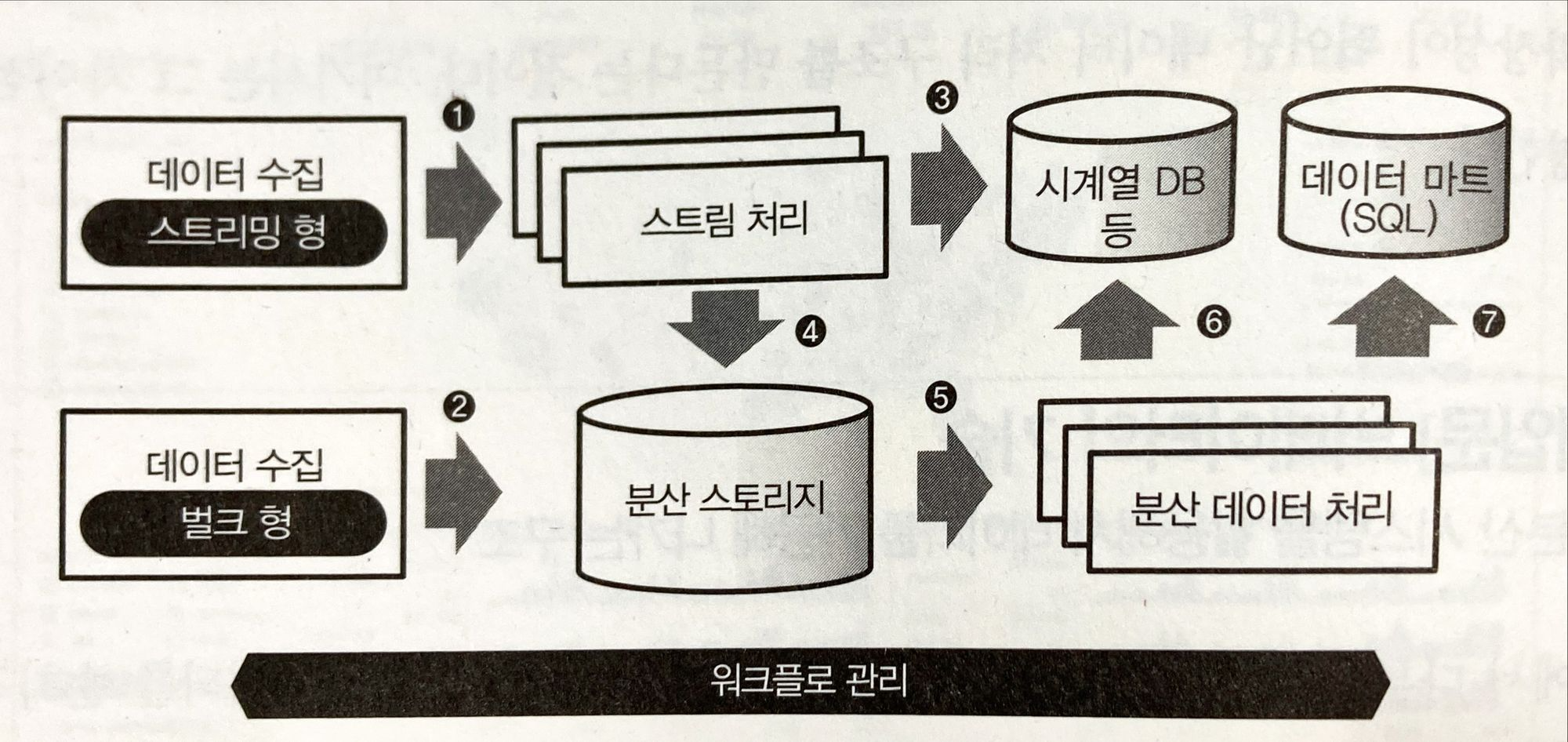
데이터 수집 - 벌크형과 스트리밍 형의 데이터 전송
데이터를 모으는 것부터 시작이다.
ex) 로그, 결제정보, 파일 등...
데이터 전송 방법은 두 가지이다.
- 벌크 형
- 스트리밍 형
벌크형 데이터와 스트리밍형 데이터 처리 프로세스
벌크형
- 어딘가에 존재하는 데이터를 정리해 추출하는 방법
- DB와 파일서버 등에 정기적으로 데이터를 수집하는 데 사용
스트리밍 형
- 끊임없이 생성되는 정보를 보내는 방법
- 모바일이나 임베디드 장비 등에서 많이 사용됨
스트림 처리와 배치 처리
기존의 벌크형에서 점차 스트리밍 형으로 넘어가고 있음
스트리밍 형을 위해서 스트림 처리가 중요해짐
스트림 처리는 실시간 데이터 처리에 강점이 있음
장기 데이터는 적합하지 않음
분산 스토리지 - 객체 스토리지, NoSQL 데이터베이스
수집된 데이터는 분산 스토리지에 저장된다.
분산 스토리지는 여러 컴퓨터와 디스크로 구성된 스토리지 시스템이다.
객체 스토리지란 한 덩어리로 모인 데이터에 이름을 부여해서 파일로 저장한다 (ex. S3)
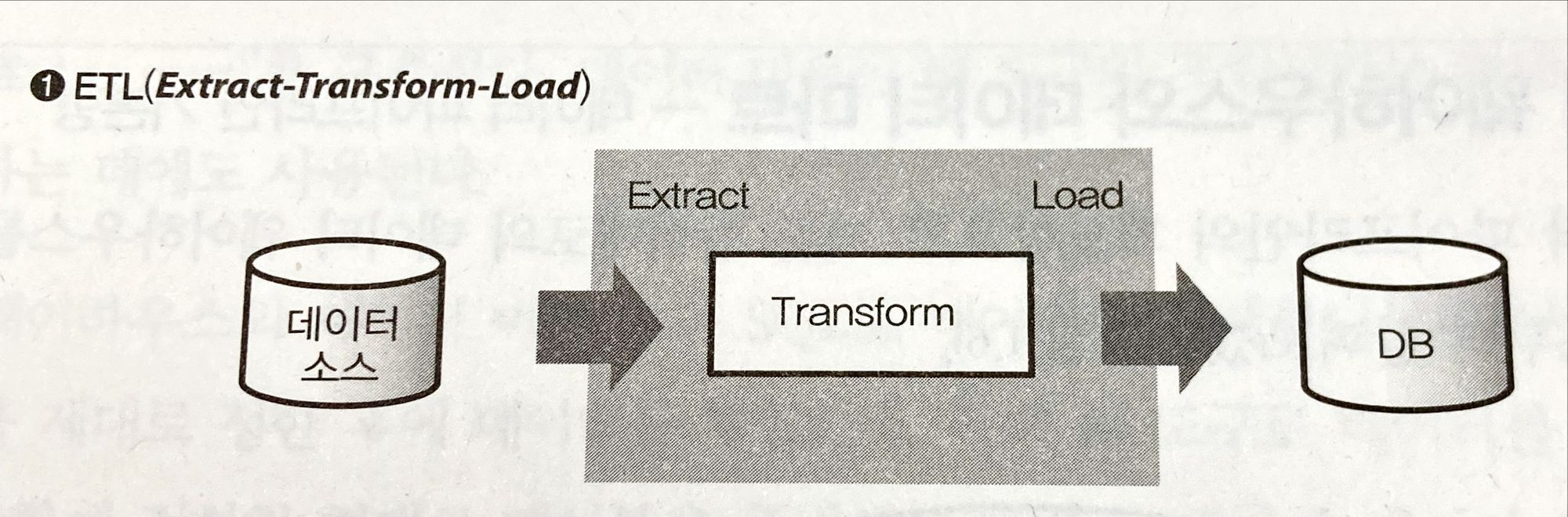
분산 데이터 처리 - 쿼리 엔진, ETL 프로세스
분산 스토리지에 저장된 데이터를 처리하는데 분산 데이터 처리 프레임워크가 필요하다.
빅데이터를 SQL로 집계할 때 2가지 방법이 있다.
- 쿼리 엔진의 도입 (Hive나 대화형 쿼리 엔진과 같은 언어 도입)
- ETL 프로세스 (외부 데이터 웨어하우스로 변환)
워크플로 관리
전체 데이터 파이프라인의 동작을 관리하기 위해 워크플로 관리 기술이 활용된다.
- 매일 정해진 시간에 배치 처리를 스케줄대로 실행
- 오류가 나면 관리자에게 통지
- 데이터 흐름이 복잡해져서 워크플로가 이를 관리
- 전체 흐름을 파악하기에 좋음
- 장애 발생 대처와 재실행 로직도 포함시켜야 함
데이터 웨어하우스와 데이터 마트 - 데이터 파이프라인 기본형
데이터 웨어하우스를 구축하는 파이프라인의 기본형에 대해 알아보자.
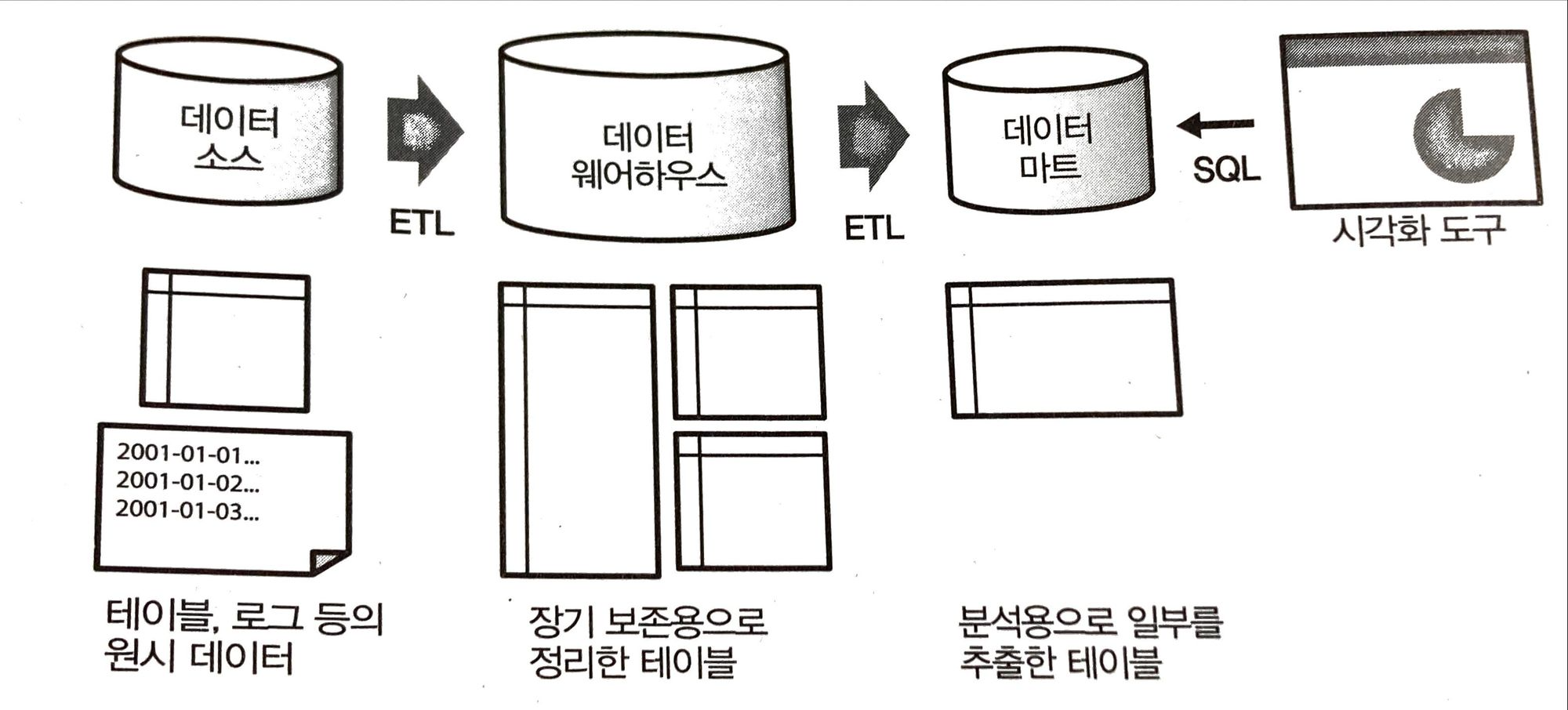
- 데이터 웨어하우스는 대량의 데이터를 장기 보존하는 것에 최적화
- 중요한 데이터를 모아둠
- 소량의 데이터를 자주 읽고 쓰는 데엔 비효율적
- 데이터 소스에서 로우 데이터를 가져오는 ETL 프로세스를 통해 데이터를 로드하고 저장
- 분석용 데이터는 데이터 마트에서 사용
- 데이터 마트는 시각화 목적에 최적화된 테이블을 구성
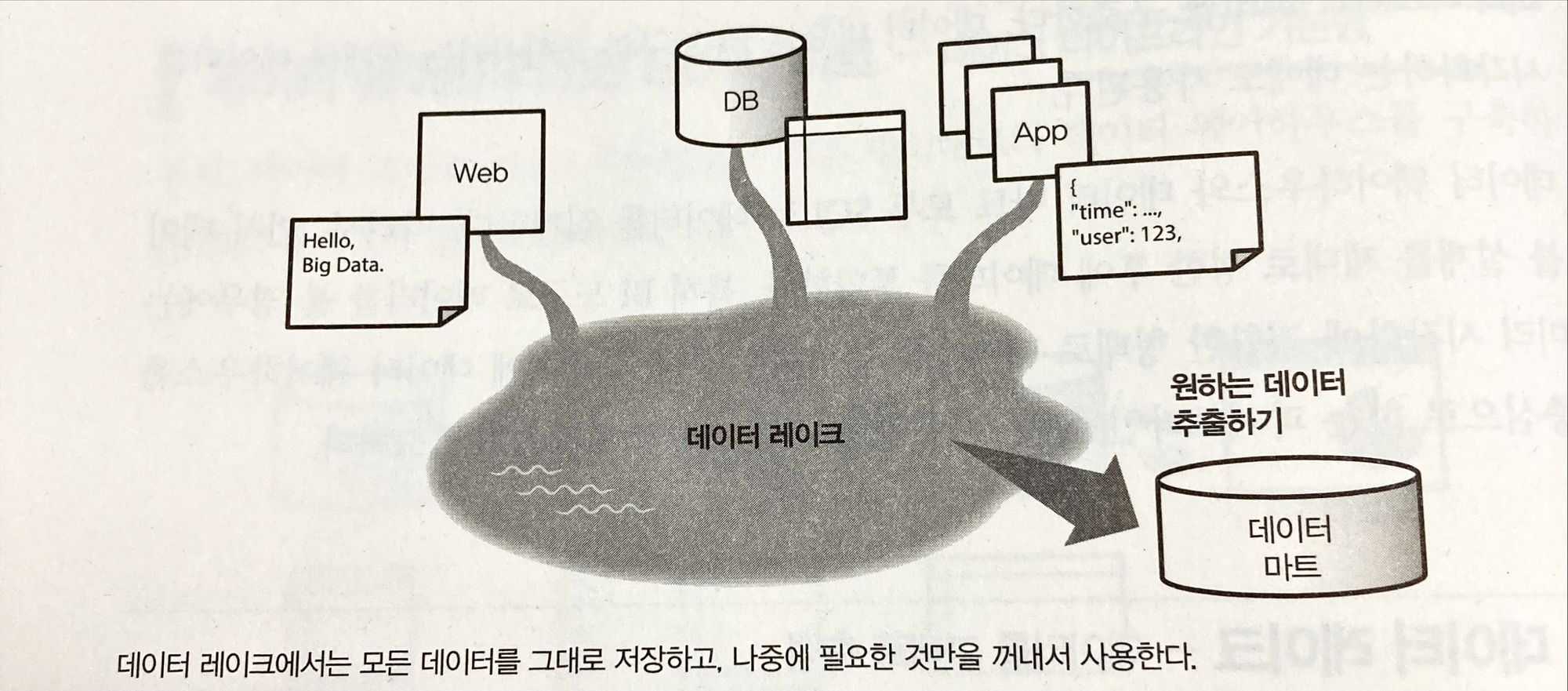
데이터 레이크 - 데이터를 그대로 축적
- ETL 프로세스가 복잡해짐
- 웨어하우스에 Row 데이터를 그대로 저장할 수 없음
- 일단 어딘가에 저장하고, 나중에 이를 정리해서 웨어하우스나 데이터 마트에 저장
→ 이 어딘가가 데이터 레이크
CSV나 JSON 같은 텍스트 파일이던 모든 데이터를 데이터 레이크에 넣어두고 나중에 가공
데이터 레이크는 단순 스토리지 역할
데이터 분석 기반을 단계적으로 발전시키기 - 팀과 역할 분담, 스몰 스타트와 확장
- 데이터 엔지니어: 시스템의 구축 및 운용, 자동화 등을 담당
- 데이터 분석가: 데이터에서 가치 있는 정보를 추출
애드 훅 분석 (ad hoc analysis)
시작단계에 수작업으로 데이터를 집계하여 분석하는 것
SQL 쿼리를 실행하거나 스프레드시트를 사용
정기적인 그래프나 보고서를 원할 땐 대시보드 도구 사용
데이터 마트와 워크플로 관리
BI 도구 사용 시 속도 문제 때문에 데이터 마트가 필수
보통 배치로 자동화 → 워크플로 도구 활용 → 엔지니어링 작업 증가
데이터를 수집하는 목적 - 검색, 가공, 시각화
- 데이터 검색: 조건에 맞는 정보를 실시간으로 찾는 기능
- 데이터 가공: 데이터 처리 결과를 활용 → 자동화 필수
- 데이터 시각화: 시각적으로 정보를 파악 → 데이터 마트 필요
→ 어떤 목적인지에 따라 시스템 구성이 달라짐
→ 기간계 시스템과 정보계 시스템을 분리해야 함
확증적 데이터 분석과 탐색적 데이터 분석
- 확증적 데이터 분석: 가설을 세우고 이를 검증하는 분석 (통계적 모델링)
- 탐색적 데이터 분석: 데이터를 시각화하고 의미를 읽어내는 분석
1-3 속성학습 스크립트 언어에 의한 특별 분석과 데이터 프레임
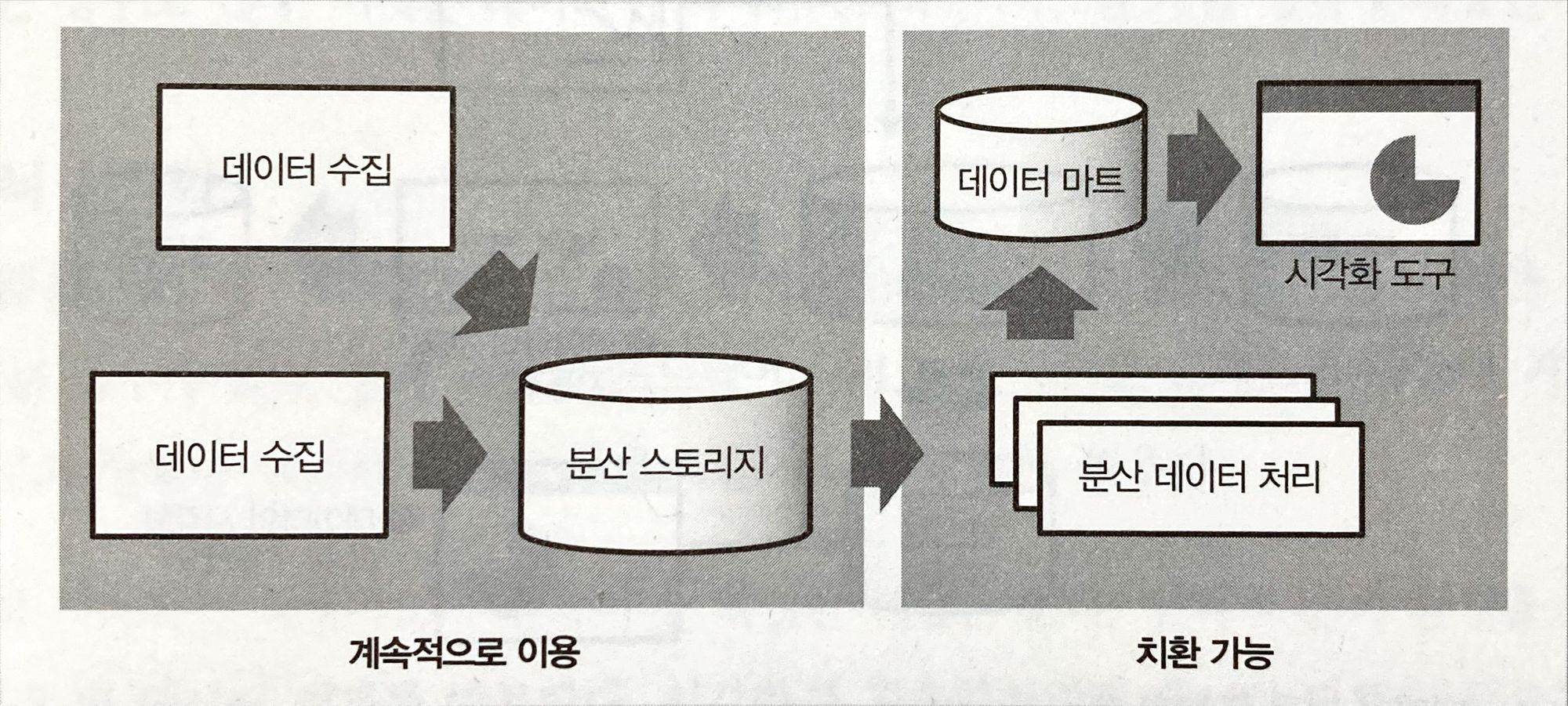
(별첨) 데이터 파이프라인의 큰 흐름은 변하지 않는다.
- 저장할 수 있는 데이터 용량에 제한이 없을 것
- 데이터를 효율적으로 추출할 수단이 있을 것
→ 데이터를 모으고, 가공하고, 시각화 도구까지 사용하는 일련의 흐름
→ 워크플로 관리가 핵심